 bmann.ca
bmann.ca
-1
.gitignore
-1
.gitignore
+3
-1
.obsidian/core-plugins.json
+3
-1
.obsidian/core-plugins.json
+146
Clippings/3W for In-Browser AI WebLLM + WASM + WebWorkers.md
+146
Clippings/3W for In-Browser AI WebLLM + WASM + WebWorkers.md
···+description: "🤝This is the first \"guest post\" in Mozilla.ai's blog (congratulations Baris!). His experiment, built upon the ideas of Mozilla.ai’s WASM agents blueprint, extends the concept of in-browser agents with local inference, multi-language runtimes, and full browser-native execution. As we are exploring ways to give users more control"+**This is the first "guest post" in Mozilla.ai's blog (congratulations Baris!). His experiment, built upon the ideas of Mozilla.ai’s** [**WASM agents blueprint**](https://blog.mozilla.ai/wasm-agents-ai-agents-running-in-your-browser/)**, extends the concept of in-browser agents with local inference, multi-language runtimes, and full browser-native execution. As we are exploring ways to give users more control over their AI technologies, we appreciate this community-led contribution and are excited to feature it here. Thank you Baris!**+What if AI agents could run entirely in your browser? Not just the UI part—the actual model inference, agent logic, and response generation, all happening locally without a single API call. It sounds impractical until you consider the pieces that are already there: WebLLM loads quantized models directly in browsers, WebAssembly compiles agent logic to near-native performance, and WebWorkers orchestrate both the model inference and agent execution off the main thread for responsive UIs.+I've been experimenting with this stack recently—compiling agent logic to WASM from different languages (Rust, Go, Python via Pyodide, JavaScript) and focusing on orchestrating everything through WebWorkers while WebLLM handles the heavy lifting for the AI Agent. The result is surprisingly capable: agents that work offline, keep data completely local, and respond faster than you'd expect from browser-based inference.+Browser-based AI today suffers from a fundamental mismatch: we build sophisticated frontends that are ultimately just fancy HTTP clients to distant GPU clusters. Even the well-fitting AI interfaces inherit all the classic web problems—unpredictable costs, privacy black holes, reliability issues, and zero control over what actually runs where. You're essentially at the mercy of someone else's infrastructure, billing model, and data handling practices. But some researchers have started pushing back against this paradigm, exploring what's possible when you keep everything client-side.+The initial inspiration came from Mozilla.ai’s excellent work on WASM agents, which demonstrated a breakthrough approach: Python agents running via Pyodide with clean integrations to OpenAI-compatible services through their [Agent SDK](https://openai.github.io/openai-agents-python/?ref=blog.mozilla.ai). Their work proved that browser-native agent execution was not only possible but practical, eliminating the complexity of local installations and dependency management.+While good as a proof-of-concept, [Mozilla.ai](http://mozilla.ai/?ref=blog.mozilla.ai) ’s work still had a few limitations. On the one hand, Pyodide brings some restrictions on the python packages that one could use. On the other hand, while the wasm-agents blueprint provides examples of local inference, this is still external to where the agent code runs (i.e. the browser), and it requires the installation of a separate inference server such as Ollama or LM Studio.+Building on this foundation, I started exploring: what if we took the next step? Instead of shipping prompts to external models, what if we shipped models to browsers entirely? Could we combine the very latest “WASM-ified Python” approach with fully local inference?+This question actually emerged from my ongoing work on Asklet, an open benchmarking sandbox for testing local LLM inference performance across modern frontend frameworks like React, Svelte, and Qwik using WebLLM and LangChain.js. While building Asklet to answer questions like "How efficient is local inference for real-world prompts across frameworks?" I discovered Mozilla.ai's work—and realized we were both pushing toward the same vision from different angles. Their agent-focused approach combined with my performance benchmarking experiments pointed toward something bigger: a complete rethinking of how AI applications could work in browsers.+The 3W stack takes this concept to its logical conclusion. The "3W" emerged from realizing that three technologies starting with "W" solve the fundamental constraints of browser AI: WebLLM eliminates remote API dependencies by handling model loading and inference locally—think 7B parameter models compressed to run efficiently in browser memory. WASM eliminates performance bottlenecks by giving us the performance layer for agent logic without the overhead of interpreted JavaScript. WebWorkers eliminate UI blocking by ensuring that while a 7B model is crunching through tokens, your UI stays responsive. Each W addresses a different bottleneck, but together they enable something that wasn't possible before.++But how do you actually architect this? From my experience building multi-threaded browser applications, the key insight is treating each programming language as a first-class runtime with its own dedicated execution context and optimized model selection. Traditional WebWorker approaches still bottleneck on shared JavaScript execution—here, so each worker gets its own WASM runtime and WebLLM engine instance, also coming with its own caching functionality.+The blueprint implements a parallel multi-runtime architecture where each programming language gets its own dedicated WebWorker thread, WASM runtime, and WebLLM engine instance. This design eliminates the traditional bottleneck of single-threaded browser JavaScript while enabling true language-specific optimizations.+The Core Architecture consists of five key layers: The main UI thread orchestrates user interactions and manages four dedicated WebWorker threads (one each for Rust, Go, Python, and JavaScript). Each worker operates independently, loading its respective WASM runtime—wasm-bindgen (with [wasm-pack](https://github.com/drager/wasm-pack?ref=blog.mozilla.ai)) for Rust, wasm\_exec.js (via [GOOS & GOARCH arguments](https://go.dev/wiki/WebAssembly?ref=blog.mozilla.ai)) for Go, [Pyodide](https://pyodide.org/en/stable/?ref=blog.mozilla.ai) for Python, and native JavaScript execution. Comlink provides a simple RPC communication between the main thread (of the browser) and workers, eliminating the typical [postMessage](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage?ref=blog.mozilla.ai) complexity.++What I found most interesting about this approach is the possibility for someone to use different models depending on the agent they use. We can expect custom agents to be available in the future that rely both on ad-hoc models and different programming languages, depending on their specific tasks. Here different runtimes can target different model classes based on the problem they need to solve. Each WebLLM engine instance is independently initialized within its worker context, allowing for dynamic model switching without affecting other runtimes.+The user experience is straightforward: select a runtime (Rust, Go, Python, or JavaScript), choose an appropriate model from that runtime's optimized selection, and start interacting. Behind the scenes, the main thread spawns the selected WebWorker, which initializes its WASM runtime and loads the chosen WebLLM model. When you submit a prompt, your WASM-compiled agent logic processes the input (generating a greeting in your selected language), then feeds both the greeting and your prompt to the local LLM for contextual response generation. All of this happens entirely in your browser—no API calls, no data leaving your device.++Getting started is straightforward—I've prioritized Docker deployment to eliminate the usual WASM toolchain hassles. If you want to jump straight in, the containerized approach handles all the build dependencies automatically.+You can pull and run the latest version of the project as a Docker container from [Docker Hub](https://hub.docker.com/repository/docker/hwclass/wasm-browser-agents-blueprint/general?ref=blog.mozilla.ai) as follows:+Navigate to ***http://localhost:5173*** and you'll see the demo interface. (Port 5173 is [Vite's default](https://vite.dev/config/server-options.html?ref=blog.mozilla.ai#server-port) —I kept the standard to maintain consistency with modern frontend tooling.) The first model load takes time—especially for the larger models like DeepSeek-8B—but subsequent interactions are surprisingly fast. Try switching between runtimes to feel the performance differences: Rust with DeepSeek feels more deliberate but comprehensive, while JavaScript with TinyLlama is snappy but lighter on reasoning.++At any time you can see what is happening in the Console tab of your browser’s Developer Tools (the system has been tested with the latest Chrome).You can try it on other browsers, too, as there is/are no any browser-specific details, [WASM support](https://caniuse.com/wasm?ref=blog.mozilla.ai) and [webgpu](https://webgpureport.org/?ref=blog.mozilla.ai) are the only dependencies here.+Once running, try asking the same question across different runtimes. The model responses vary not just due to different models, but because each runtime's greeting logic creates slightly different context prompts. This isn't a bug—it's a feature that demonstrates how language-specific agent logic can influence AI behavior in subtle ways.+Beyond the technical novelty, this architecture opens up application categories that weren't practical before. Think browser-based development tools that can analyze code locally without sending it to external services—perfect for sensitive codebases or offline environments, like how you do with the most famous IDEs. Documentation systems that can answer questions about your project using models trained on your specific codebase, running entirely client-side. Or anything running with prioritized privacy.+The multi-language approach becomes powerful when you consider domain-specific agents: financial modeling agents in Rust for precision, data processing agents in Go for concurrency, research prototyping in Python for flexibility, and UI interaction agents in JavaScript for responsiveness. Each language handles what it does best, but they all share the same local inference infrastructure - browser as a runtime for AI inference.++Why choose this over alternatives? Most browser AI (also with agent workload) solutions today require API keys, internet connectivity, and data transmission to third parties. This approach eliminates those dependencies while giving you direct control over model selection and agent behavior. Unlike server-side solutions, there's no scaling costs—each user brings their own compute. Unlike purely JavaScript solutions, you get the full performance spectrum from lightweight TinyLlama interactions to serious DeepSeek reasoning.+The real potential lies in applications we haven't thought of yet: in-browser dev environments with AI pairing, offline-first AI tools for field work, privacy-focused AI applications for healthcare or legal work, educational tools that don't require institutional API access. When AI processing happens locally, entirely new categories of applications become possible.+Building this taught me that browser AI has sharp edges—and they're not always where you'd expect. Model loading is the biggest UX challenge: DeepSeek-8B takes 2-3 minutes to download and initialize on a decent connection, during which users see a progress bar and wonder if something's broken. Once loaded, inference is surprisingly “fast” on a Mac M2 Pro —often faster than API round-trips—but that initial wait is brutal for user expectations.+**Memory is the real constraint.** The 8GB Docker recommendation isn't arbitrary—running multiple WebLLM instances simultaneously can quickly exhaust browser memory limits. I've seen Chrome tabs crash when users try to switch between runtime models too quickly without proper cleanup. The current architecture terminates and reinitializes engines on model switches, which works but feels wasteful when you know the models could theoretically coexist.+**Runtime performance varies more than I expected.** Rust with wasm-bindgen consistently delivers the fastest WASM execution, but the JavaScript native implementation sometimes wins on pure responsiveness because it skips the WASM boundary entirely. Python via Pyodide is surprisingly capable but has unpredictable memory spikes. Go sits in a sweet spot—reliable, efficient, but not always the fastest at either compute or responsiveness.+**Hardware constraints bite hard.** What runs smoothly on an M3 MacBook barely functions on older hardware. Mobile devices? Forget about the larger models entirely. This isn't a universal solution—it's a high-end browser solution that assumes recent hardware and generous memory limits. The lightweight models (TinyLlama, Phi-1.5) democratize access somewhat, but they also deliver noticeably lighter reasoning capabilities.+**Honest assessment:** This browser-first approach effectively reduces server costs and privacy risks, but demands more from local hardware and has slow startups—great for niche use cases, not yet mainstream.+Playing devil’s advocate, it’s worth noting this isn’t running true agents (not yet, the handoff and tool-calling examples are on their way)—only interfacing with LLMs for now. It’s a proof-of-concept, and with future agentic models in WebLLM (or better alternatives), real agent capability is definitely on the horizon.+Several architectural improvements could significantly enhance this approach. The current implementation works, but it's clearly a first iteration with room for optimization. Here the list of what I can count in the first glance:+**SharedWorker Architecture:** Enablement of multitab and multisession model sharing to reduce load times and duplicate downloads.+**Advanced Model Caching:** To make a move beyond IndexedDB by using service workers, persistent storage APIs, and smart eviction policies for offline and robust model management.+**JavaScript PubSub Event Bus:** Native event-driven communication between browser agents can provide flexible tool orchestration (JS events, handoffs across languages) as JS itself inherits an event-driven paradigm due to where it was born = browsers.+**Broadcast Channel API for Cross-Tab Coordination:** An universalised event bus for distributed agents across multiple tabs/windows with unified state and messaging.+**Background Sync Model Downloads:** To fetch and cache models opportunistically by utilising Background Sync and Service Workers, allowing offline-first PWA experiences.+**AI-Native Browser Runtimes:** Providing optimized in-browser inference with headless/AI-first browsers (e.g. Lightpanda, Firefox AI Extension API).+**Embedded Runtimes (QuickJS & WasmEdge):** Move from retrofitting web technologies to purpose-built, lightweight JavaScript/AI inference engines assuming browsers as runtimes running on edge devices.+**In-Browser RAG Data Processing:** Utilising tools like DuckDB (with VSS plugin) and PyArrow for fast, local, semantic search and data science workloads directly in the browser opens another gate to discover more use cases.+**Multi-Language Agent Playbooks:** Interactive, browser-native notebooks for experimenting with cross-language agent workflows and runtimes.+**Memory Management Innovations:** Shared model weights across WASM instances, improve garbage collection, and lower browser memory spikes.+**Progressive Model Loading:** To improve initial load responsiveness, streaming models in chunks and enable basic functionality early.+For a deep dive into these architectural enhancements and practical implementation tips, check out the complete article [on my blog](https://hwclass.dev/posts/beyond-the-browser-within-the-browser-browser-apis-for-an-ai-native-approach?ref=blog.mozilla.ai).+I honestly don't know yet whether browser-native AI agents are the future or an interesting dead end. But they scratch an itch I've had for years about where computation should happen and who should control it. There's something deeply satisfying about watching a 7B parameter model reason through problems entirely on your machine, using whatever programming language makes sense for the task, without a single bit of data leaving your browser.+Building on Mozilla.ai’s foundational work, this 3W approach tries to push the boundaries of what's possible when you refuse to accept the server-dependency status quo. The architecture has sharp edges—memory constraints, initialization delays, hardware requirements—but it also enables application categories that simply weren't feasible before. Privacy-first AI tools, offline-capable intelligent applications, and multi-language agent systems that leverage each runtime's strengths.+The enhancement areas I've outlined aren't just technical improvements; they're potential paths toward making browser-native AI genuinely competitive with server-based solutions. The PubSub coordination layer alone could transform this from a clever demo into a practical development platform for distributed in-browser intelligence, for example.+This is experimental software, shared early and openly. I’m genuinely curious—what would you build with this architecture, and what new directions could it take? If you’re interested in agentic workflows, try extending this to run true agents with tool-calling (think Rust or Python frameworks—maybe even overcoming some pyodide limitations). Or, if you’re keen on browser integrations, consider exploring internal model support in Firefox (I’d especially love feedback here!).+The code is on [GitHub](http://github.com/hwclass/wasm-browser-agents-blueprint/?ref=blog.mozilla.ai) and the provided containers make for easy experimenting. If you dig in, please share your results, hacks, or directions you think are worth exploring next—I’m all ears.+Sometimes the most interesting technical problems come from asking simple questions: What if we just... didn't send our data to someone else's computer? The 3W stack is the one looking for the right answer to that question. Whether it's the right answer remains to be seen.
+98
Clippings/Bluesky Leaves Mississippi. What Happens Next.md
+98
Clippings/Bluesky Leaves Mississippi. What Happens Next.md
···+description: "Bluesky’s decision to drop out of the Mississippi market shows we cannot take our digital access for granted. The next steps matter."+[About](https://tedium.co/what-is-tedium) / [Archives](https://tedium.co/archive) / [Sponsor Us](https://tedium.co/advertising) :format(jpeg)/uploads/misssissippi_2025-08-23-045225_uerx.gif) /uploads/misssissippi_2025-08-23-045225_uerx.gif)+[ ShareOpenly](https://shareopenly.org/share/?url=https%3A%2F%2Ftedium.co%2F2025%2F08%2F23%2Fbluesky-mississippi-reaction&text=https%3A%2F%2Ftedium.co%2F2025%2F08%2F23%2Fbluesky-mississippi-reaction%3A%20Bluesky%E2%80%99s%20decision%20to%20drop%20out%20of%20the%20Mississippi%20market%2C%20while%20understandable%2C%20is%20a%20clear%20sign%20that%20we%20cannot%20take%20our%20digital%20access%20for%20granted.) [Share Well](https://toot.kytta.dev/?text=Blue%20In%20Mississippi%3A%20Bluesky%E2%80%99s%20decision%20to%20drop%20out%20of%20the%20Mississippi%20market%2C%20while%20understandable%2C%20is%20a%20clear%20sign%20that%20we%20cannot%20take%20our%20digital%20access%20for%20granted.%0A%0Ahttps%3A%2F%2Ftedium.co%2F2025%2F08%2F23%2Fbluesky-mississippi-reaction%0A%0A%28via%20%40tedium%40social%2Etedium%2Eco%29) [Share Amazingly](https://bsky.app/intent/compose?text=Blue%20In%20Mississippi%3A%20Bluesky%E2%80%99s%20decision%20to%20drop%20out%20of%20the%20Mississippi%20market%2C%20while%20understandable%2C%20is%20a%20clear%20sign%20that%20we%20cannot%20take%20our%20digital%20access%20for%20granted.%20https%3A%2F%2Ftedium.co%2F2025%2F08%2F23%2Fbluesky-mississippi-reaction)+**When I first got on the internet** in the mid-’90s, much of my interest in tech was driven by the access to resources I did not immediately have access to through traditional means.+One of the first ways I used the internet was by dialing up a Free-Net line, getting in the Lynx browser, and seeing how far I could get. Often, the sysop kicked me off within about five minutes, but sometimes I managed to get pretty far.+As I could not type in any web addresses myself, my goal was to keep clicking until I found something that looked like the “real” internet. Sometimes, I got lucky.+But a new law recently passed in Mississippi, like that passed in the U.K., wants to limit who can access the social media platforms to those willing to share their identity, and the cited reason for doing so is kids. (The law was named for a teen who committed suicide as the result of a [catfishing incident](https://www.clarionledger.com/story/news/2023/02/22/starkville-dad-talks-of-social-media-dangers-after-sons-suicide-sextortion/69926741007/), and passed with bipartisan support. A small tug at heartstrings can do a lot of damage.)+With a court ruling [letting the law go through](https://www.npr.org/2025/08/14/nx-s1-5482925/scotus-netchoice) for now, despite the fact that it is likely to fail on First Amendment grounds in a higher court, Bluesky has decided not to test the legal system.+On Friday, [it announced](https://bsky.social/about/blog/08-22-2025-mississippi-hb1126) that it would no longer operate in the state—creating the perfect example of a patchwork of laws that many worry about. In a blog post announcing the move:+> Unlike tech giants with vast resources, we’re a small team focused on building decentralized social technology that puts users in control. Age verification systems require substantial infrastructure and developer time investments, complex privacy protections, and ongoing compliance monitoring—costs that can easily overwhelm smaller providers. This dynamic entrenches existing big tech platforms while stifling the innovation and competition that benefits users.+> We believe effective child safety policies should be carefully tailored to address real harms, without creating huge obstacles for smaller providers and resulting in negative consequences for free expression. That’s why until legal challenges to this law are resolved, we’ve made the difficult decision to block access from Mississippi IP addresses. We know this is disappointing for our users in Mississippi, but we believe this is a necessary measure while the courts review the legal arguments.+/uploads/bafkreiah2kgmaxc5eyzayw2hawy5ngs2um353snkyojy2b6qysccwaxbem.jpg)+The message might look strangely familiar to anyone who lives in a state where certain adult content providers have left. And yes, it is very likely that people will use the same methods that those users rely on to access those adult sites. VPNs blew up in popularity in the U.K. recently as a result of its [Online Safety Act](https://www.eff.org/deeplinks/2025/08/no-uks-online-safety-act-doesnt-make-children-safer-online).+The Bluesky blog noted that the Mississippi law is even more extreme than the Online Safety Act, if that is even possible:+> Mississippi’s new law and the UK’s Online Safety Act (OSA) are very different. Bluesky [follows](https://bsky.social/about/blog/07-10-2025-age-assurance) the OSA in the UK. There, Bluesky is still accessible for everyone, age checks are required only for accessing certain content and features, and Bluesky does not know and does not track which UK users are under 18. Mississippi’s law, by contrast, would block everyone from accessing the site—teens and adults—unless they hand over sensitive information, and once they do, the law in Mississippi requires Bluesky to keep track of which users are children.+At least one publication in the state, the Mississippi Free Press, has a very large platform on Bluesky, and they [may be at risk of losing that megaphone](https://www.mississippifreepress.org/editors-note-bluesky-blocks-mississippi-ips-citing-states-age-verification-law-free-speech-and-privacy-concerns/), which puts a focus on the issues facing their state.+“As a nonprofit publication, we do not take positions on specific legislation or laws,” editor Ashton Pittman wrote. “But whatever the Mississippi Legislature’s intent, we now find ourselves in a place where we are now having to grapple with how to ensure we can stay connected with all of our readers, many of whom follow us on Bluesky.”+I have a feeling that what may happen as a result of all of this is that we will gradually begin to decentralize more. Part of the reason big platforms full of user-generated content are targets is because they create a fulcrum that lawmakers can target.+They have figured out that putting a lean on a few key issues will make it easier to restrict information online, because they are hard to compete against in the court of public opinion.+The good news is that, like the fediverse, Bluesky has stronger underpinnings than your average social network. You don’t have to use the Bluesky client. Nor do you have to live on the Bluesky network to communicate with the [AT Protocol](https://atproto.com/). External clients could help in a big way.+I asked Anuj Ahooja, the CEO and executive director of [A New Social](https://anew.social/), a nonprofit working to build distributed social technology that works across protocols, what he thought of this situation. He says this moment could be an opportunity to “to decouple peoples’ networks from platforms.”+“When platforms make decisions that have an impact on peoples’ livelihood, whether forced or not, people should be able to escape without having to leave their communities behind,” he says.+/uploads/Bounce-Screenshot-2.jpg)+On top of the nonprofit’s stewardship of the popular [Bridgy Fed](https://fed.brid.gy/) tool, the organization is in the midst of launching its [Bounce tool](https://blog.anew.social/bounce-a-cross-protocol-migration-tool/), which makes it possible to migrate social graphs between Mastodon and Bluesky. For media outlets at risk of getting disconnected from an important platform, for example, this could be a powerful tool.+“The combination of Bridgy Fed and Bounce gives them an exit strategy that lets them preserve their existing communities and relationships,” he adds.+You do not have to use Bluesky to talk to Bluesky, and in a moment like this, that’s a superpower. You can use external clients. You can host your server somewhere other than the Bluesky network. An escape hatch is possible—and companies like [Blacksky](https://www.blackskyweb.xyz/) are already cropping up to help make this hatch a reality.+Other social networks need to take notes, as they will need technical infrastructure to survive this moment. Even if the bug in Mississippi gets squashed, someone else will make another one. We need to be prepared for any situation as it arises.+In an age of platforms, we have constantly let the desire to make money and get reach take a backseat to actually owning our infrastructure. It’s moments like this that offer excellent reminders why that matters.+As I wrote last year, the real opportunity for Bluesky was not in the social network but the opportunities it opened up for tools to be built on this protocol. If played correctly, this could be the moment where those opportunities flourish.+But I have to admit: I worry about the 13-year-old, still trying to figure out who they are, getting online and having a huge section of the digital discourse blocked off to them. That makes it harder to figure out who they really are or what they care about.+I don’t want to sound like too much of a downer here but we need to be realistic. The internet as we know it is at risk, and just as fundamental protocols enabled it, fundamental protocols will save it.+Maybe those 13-year-olds will get clever like I did and accidentally find a way to reach the good parts of the internet. Laws like the ones in Mississippi tend to forgot that those exist.+**To those of you** who had to throw out [radioactive shrimp](https://futurism.com/walmart-shrimp-radioactive) this week: Hey, at least you got a good story out of it.+**The best parody videos** are the ones parodying very old YouTube videos you’ve likely forgotten about. Such is the case of [this comedic clip](https://www.youtube.com/watch?v=bl8Z7Dl7P9A) of a professor having a mental breakdown because his class cheated on an exam, based on a 14-year-old clip of a professor dressing down his class for 15 minutes. (It has [16 million views](https://www.youtube.com/watch?v=rbzJTTDO9f4).)+**I’m honestly kind of sick** of Substack at this point, but their App Store policy sets a really dangerous, but subtle precedent. Because people can now pay for a subscription [through the App Store](https://techcrunch.com/2025/08/18/substack-writers-can-now-direct-u-s-readers-to-often-cheaper-web-based-subscriptions-on-ios/), it is now harder for Substack publishers to leave. [Isabelle Roughol has the explainer](https://www.isabelleroughol.com/lede/how-substack-delivered-its-users-onto-apple/).+Find this one an interesting read? [Share it with a pal](https://tedium.co/2025/08/23/bluesky-mississippi-reaction/). And to the folks in Mississippi suddenly without easy access to Bluesky, there is a path forward here—just keep that in mind.+/uploads/ernie_crop.jpg) Your time was wasted by … Ernie Smith is the editor of Tedium, and an active internet snarker. Between his many internet side projects, he finds time to hang out with his wife Cat, who's funnier than he is.
+123
Clippings/Funding Open Source like public infrastructure.md
+123
Clippings/Funding Open Source like public infrastructure.md
···+description: "To protect the digital foundation of essential government services, governments should invest in Open Source as public infrastructure and shift from consumption to contribution."+To protect the digital foundation of essential government services, governments should invest in Open Source as public infrastructure and shift from consumption to contribution.++An illustration of a small wedge propping up a massive block, symbolizing how a small group of contributors supports critical infrastructure.+Fifteen years ago, I laid out a theory about the future of Open Source. In [*The Commercialization of a Volunteer-Driven Open Source Project*](https://dri.es/the-commercialization-of-a-volunteer-driven-open-source-project), I argued that if Open Source was going to thrive, people had to get paid to work on it. At the time, the idea was controversial. Many feared money would corrupt the spirit of volunteerism and change the nature of Open Source contribution.+In that same post, I actually went beyond discussing the case for commercial sponsorship and outlined a broader pattern I believed Open Source would follow. I suggested it would develop in three stages: (1) starting with volunteers, then (2) expanding to include commercial involvement and sponsorship, and finally (3) gaining government support.+I based this on how other [public goods](https://en.wikipedia.org/wiki/Public_good) and public infrastructure have evolved. Trade routes, for example, began as volunteer-built paths, were improved for commerce by private companies, and later became government-run. The same pattern shaped schools, national defense, and many other public services. What begins as a volunteer effort often ends up being maintained by governments for the benefit of society. I suggested that Open Source would and should follow the same three-phase path.+Over the past fifteen years, paying people to maintain Open Source has shifted from controversial to widely accepted. Platforms like [Open Collective](https://opencollective.com/), an organization I invested in as an angel investor in 2015, have helped make this possible by giving Open Source communities an easy way to receive and manage funding transparently.+Today, Open Source runs much of the world's critical infrastructure. It powers government services, supports national security, and enables everything from public health systems to elections. This reliance means the third and final step in its evolution is here: governments must help fund Open Source.+Public funding would complement the role of volunteers and commercial sponsors, not replace them. This is not charity or a waste of tax money. It is an investment in the software that runs our essential services. Without it, we leave critical infrastructure fragile at the moment the world needs it most.+A 2024 Harvard Business School study, [*The Value of Open Source Software*](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4693148), estimates that replacing the most widely used Open Source software would cost the world $8.8 trillion. If Open Source suddenly disappeared, organizations would have to spend 3.5 times more on software than they do today. Even more striking: 96% of that $8.8 trillion depends on just 5% of contributors.+This concentration creates fragility. Most of our digital infrastructure depends on a small group of maintainers who often lack stable funding or long-term support. When they burn out or step away, critical systems can be at risk.+Maintaining Open Source is not free. It takes developers to fix bugs, maintainers to coordinate releases, security teams to patch vulnerabilities, and usability experts to keep the software accessible. Without reliable funding, these essential tasks are difficult to sustain, leaving the foundations of our digital society exposed to risk.+Addressing this risk means rethinking not just funding, but also governance, succession planning, and how we support the people and projects that keep our society running.+Recent geopolitical tensions and policy unpredictability have made governments more aware of the risks of relying on foreign-controlled, proprietary software. Around the world, there is growing recognition that they cannot afford to lose control over their digital infrastructure.+[Denmark recently announced a national plan](https://interoperable-europe.ec.europa.eu/collection/open-source-observatory-osor/news/denmark-embraces-open-source-software) to reduce their dependency on proprietary software by adopting Open Source tools across its public sector.+This reflects a simple reality: when critical public services depend on foreign-controlled software, governments lose the ability to guarantee continuity and security to their citizens. They become vulnerable to policy changes and geopolitical pressures beyond their control.+As [Denmark's Ministry for Digitalisation explained](https://interoperable-europe.ec.europa.eu/collection/open-source-observatory-osor/news/denmark-embraces-open-source-software), this shift is about control, accountability, and resilience, not just cost savings. Other European cities and countries are developing similar strategies. This is no longer just an IT decision, but a strategic necessity for protecting national security and guaranteeing the continuity of essential public services.+Most government institutions rely heavily on Open Source but contribute little in return. Sponsorship usually flows through vendor contracts, and while some vendors contribute upstream, the overall level of support is small compared to how much these institutions depend on said projects.+Procurement practices often make the problem worse. Contracts are typically awarded to the lowest bidder or to large, well-known IT vendors rather than those with deep Open Source expertise and a track record of contributing back. Companies that help maintain Open Source projects are often undercut by firms that give nothing in return. This creates a race to the bottom that ultimately weakens the Open Source projects governments rely on.+As I discussed in [*Balancing makers and takers to scale and sustain Open Source*](https://dri.es/balancing-makers-and-takers-to-scale-and-sustain-open-source), sustainable Open Source requires addressing the fundamental mismatch between use and contribution.+Governments need to shift from Open Source consumption to Open Source contribution. The digital infrastructure that powers government services demands the same investment commitment as the roads and bridges that connect our communities.+I have helped lead [Drupal](https://www.drupal.org/) for almost 25 years, and in that time I have seen how deeply governments depend on Open Source.+The European Commission runs more than a hundred Drupal sites, France operates over a thousand Drupal sites, and Australia's government has standardized on Drupal as its national digital platform. Yet despite this widespread use, most of these institutions contribute little back to Drupal's development or maintenance.+This is not just a Drupal problem, and it is entirely within the rights of Open Source users. There is no requirement to contribute. But in many projects, a small group of maintainers and a few companies carry the burden for infrastructure that millions rely on. Without broader support, this imbalance risks the stability of the very systems governments depend on.+Many public institutions use Open Source without contributing to its upkeep. While this is legal, it shifts all maintenance costs onto a small group of contributors. Over time, that risks the services those institutions depend on. Better procurement and policy choices could help turn more public institutions into active contributors.+I am certainly not the only one calling for government involvement in Open Source infrastructure. In recent years, national governments and intergovernmental bodies, including the United Nations, have begun increasing investment in Open Source.+In 2020, the UN Secretary General's [*Roadmap for Digital Cooperation*](https://www.un.org/en/content/digital-cooperation-roadmap/) called for global investment in "digital public goods" such as Open Source software to help achieve the Sustainable Development Goals. Five years later, the UN introduced the [UN Open Source Principles](https://unite.un.org/news/sixteen-organizations-endorse-un-open-source-principles), encouraging practices like "open by default" and "contributing back".+At the European level, the [EU's Cyber Resilience Act](https://en.wikipedia.org/wiki/Cyber_Resilience_Act) recognizes Open Source software stewards as "economic actors", acknowledging their role in keeping infrastructure secure and reliable. In Germany, the [Sovereign Tech Agency](https://www.sovereign.tech/) has invested €26 million in more than [60 Open Source projects](https://www.sovereign.tech/tech) that support critical digital infrastructure.+Governments and public institutions are also creating Open Source Program Offices (OSPOs) to coordinate policy, encourage contributions, and ensure long-term sustainability. In Europe, the European Commission's [EC OSPO](https://ec.social-network.europa.eu/@EC_OSPO) operates the [code.europa.eu](https://code.europa.eu/) platform for cross-border collaboration. In the United States, agencies such as the [Centers for Medicare & Medicaid Services](https://www.cms.gov/digital-service/open-source-program-office), the [United States Digital Service](https://www.usds.gov/), the [Cybersecurity and Infrastructure Security Agency](https://www.cisa.gov/), and the [U.S. Digital Corps](https://digitalcorps.gsa.gov/) play similar roles. In Latin America, Brazil's [Free Software Portal](https://softwarepublico.gov.br/) supports collaboration across governments.+These efforts signal a shift from simply using Open Source to actively stewarding and investing in it at the institutional level.+If the top 100 countries each contributed $200,000 a year to an Open Source project, the project would have a twenty million dollar annual budget. That is about what it costs to maintain less than ten miles of highway.+In my home country, Belgium, which has just over ten million people, more than one billion euros is spent each year maintaining roads. A small fraction of that could help secure the future of Open Source software like Drupal, which supports public services for millions of Belgians.+For the cost of maintaining 10 miles of highway, we could secure the future of several critical Open Source projects that power essential public services. The math borders on absurd.+Just as governments maintain roads, bridges and utilities that society depends on, they should also help sustain the Open Source projects that power essential services, digitally and otherwise. The scale of investment needed is modest compared to other public infrastructure.+- **Track the health of critical Open Source projects.** Just like we have safety ratings for bridges, governments should regularly check the health of the Open Source projects they rely on. This means setting clear targets, such as addressing security issues within *x* days, having *y* active maintainers, keeping all third-party software components up to date, and more. When a project falls behind, governments should step in and help with targeted support. This could include direct funding, employing contributors, or working with partners to stabilize the project.+- **Commit to long-term funding with stable timelines.** Just as governments plan highway maintenance years in advance, we'd benefit from multi-year funding commitments and planning for critical digital infrastructure. Long-term funding allows projects to address technical debt, plan major updates, and recruit talent without the constant uncertainty of short-term fundraising.+- **Encourage contribution in government contracts.** Governments can use procurement to strengthen the Open Source projects they depend on. Vendor contribution should be a key factor in awarding contracts, alongside price, quality, and other criteria. Agencies or vendors can be required or encouraged to give back through coding, documentation, security reviews, design work, or direct funding. This ensures governments work with true experts while helping keep critical Open Source projects healthy and sustainable.+- **Adopt "Public Money, Public Code" policies.** When taxpayer money funds software for public use, that software should be released as Open Source. This avoids duplicate spending and builds shared digital infrastructure that anyone can reuse, improve, and help secure. The principle of ["Public Money? Public Code!"](https://publiccode.eu/) offers a clear framework: code paid for by the people should be available to the people. Switzerland recently embraced this approach at the federal level with its [EMBAG law](https://interoperable-europe.ec.europa.eu/collection/open-source-observatory-osor/news/new-open-source-law-switzerland), which requires government-developed software to be published as Open Source unless third-party rights or security concerns prevent it.+- **Scale successful direct funding models.** The [Sovereign Tech Agency](https://www.sovereign.tech/) has shown how government programs can directly fund the maintenance and security of critical Open Source software. Other nations should follow and expand this model. Replacing widely used Open Source software could cost an estimated 8.8 trillion dollars. Public investment should match that importance, with sustained global funding in the billions of dollars across countries and projects.+- **Teach Open Source in public schools and universities.** Instead of relying solely on proprietary vendors like Microsoft, governments should integrate Open Source tools, practices, and values into school and university curricula, along with related areas such as open standards and open data. This prepares students to participate fully in Open Source, builds a talent pipeline that understands Open Source, and strengthens digital self-reliance.+Concerns about political interference or loss of independence are valid. That is why we need systems that allow all stakeholders to coexist without undermining each other.+Government funding should reinforce the ecosystem that makes Open Source thrive, not replace it or control it. Companies and volunteers are strong drivers of innovation, pushing forward new features, experiments, and rapid improvements. Governments are better suited to a different but equally vital role: ensuring stability, security, and long-term reliability.+The most critical tasks in Open Source are often the least glamorous. Fixing bugs, patching vulnerabilities, updating third-party dependencies, improving accessibility, and maintaining documentation rarely make headlines, but without them, innovation cannot stand on a stable base. These tasks are also the most likely to be underfunded because they do not directly generate revenue for companies, require sustained effort, and are less appealing for volunteers.+Governments already maintain roads, bridges, and utilities, infrastructure that is essential but not always profitable or exciting for the private sector. Digital infrastructure deserves the same treatment. Public investment can keep these core systems healthy, while innovation and feature direction remain in the hands of the communities and companies that know the technology best.+Fifteen years ago, I argued that Open Source needed commercial sponsorship to thrive. Now we face the next challenge: governments must shift from consuming Open Source to sustaining it.+Today, some Open Source has become public infrastructure. Leaving critical infrastructure dependent on too few maintainers is a risk no society should accept.+The solution requires coordinated policy reforms: dedicated funding mechanisms, procurement that rewards upstream contributions, and long-term investment frameworks.+*Special thanks to [Baddy Sonja Breidert](https://www.drupal.org/u/baddysonja), [Tim Doyle](https://www.drupal.org/u/tim-d), [Tiffany Farriss](https://www.drupal.org/u/farriss), [Mike Gifford](https://www.drupal.org/u/mgifford), [Owen Lansbury](https://www.drupal.org/u/owenlansbury) and [Nick Veenhof](https://www.drupal.org/u/nick_vh) for their review and contributions to this blog post.*
+26
Clippings/GitHub is ripe for disruption.md
+26
Clippings/GitHub is ripe for disruption.md
···+GitHub is ubiquitous. It feels like it has always been there and I couldn’t imagine a world without it. You might use different LLMs, IDEs, and programming languages, but everyone uses GitHub.+This isn’t to say a better version couldn’t exist and now seems like the perfect moment to make it happen. Outages seem to happen every week, it is in a [decreasingly important spot at Microsoft](https://www.theverge.com/news/757461/microsoft-github-thomas-dohmke-resignation-coreai-team-transition), and it simply hasn’t really changed (probably a good thing).+Here are some features GitHub doesn’t have that could form the basis of a disruptive competitor:+- **Live collaboration.** GitHub is a Sketch-era app. There is a [Figma](https://kwokchain.com/2020/06/19/why-figma-wins/) equivalent waiting to be built. Planning, issues, and reviews could all be rebuilt to use live collaboration. For example, why can’t I thread comments on PRs, only code comments? Why can my review overlap with someone else’s and I get no warning?+- **Tailored review interfaces.** GitHub was built for software engineers but there’s a lot more roles who rely on it now like me (a technical marketer). Review interfaces tailored to the type of content being reviewed. For example, reviewing markdown sucks and a change to a website almost always involves deploying a preview and tabbing back and forth between it and the PR. I’m sure infra or ML engineers could come up with their own requirements too.+- **AI coding.** It’s sort of forgotten that Copilot was a GitHub product. Although I’m sure it’s still used a lot, it doesn’t feel like a core part of GitHub. It’s also not on the cutting edge anymore (Claude Code, Cursor, Devin, etc.). There’s no AI interface in GitHub. Where is the issue summarization, chat with your codebase, and code generation?+- **Native AI code reviews.** Although they are the biggest new innovation in GitHub, it feels like AI code review tools like [Greptile](https://www.greptile.com/) are bolted on rather than natively supported. AI code reviewers are limited in their functionality in GitHub (only read code and comment) and largely run outside GitHub.+GitHub has been very content with its spot in the ecosystem. It has lightly reached into other areas like code editors, package management, AI code generation, and more, but not seriously. For example, GitHub owns `npm` but it feels like there is much more innovation in developer tooling elsewhere (see `uv`, [`pyx`](https://astral.sh/blog/introducing-pyx), `pnpm`, [Turbo](https://turborepo.com/), and more).+GitHub Actions is hugely successful, with a market share apparently [over 50% in CI](https://chuniversiteit.nl/papers/rise-and-fall-of-ci-services-in-github), but the company as a whole remains a big “what if” (they built 5 more similarly successful products).+Simply, the disruption caused by LLMs, code generation, and the amount of capital flowing into AI presents a huge opportunity to disrupt GitHub and become a critical (and valuable) tool in software development.
+53
Clippings/My responses to The Register.md
+53
Clippings/My responses to The Register.md
···+source: "https://xeiaso.net/notes/2025/el-reg-responses/?utm_campaign=mi_irl&utm_medium=social&utm_source=bluesky"+Today my quotes about generative AI scrapers [got published in The Register](https://www.theregister.com/2025/08/21/ai_crawler_traffic/). For transparency's sake, here's a copy of the questions I was asked and my raw, unedited responses. Enjoy!+I can only see one thing causing this to stop: the AI bubble popping. There is simply too much hype to give people worse versions of documents, emails, and websites otherwise. I don't know what this actually gives people, but our industry takes great pride in doing this.+I see no reason why it would not grow. People are using these tools to replace knowledge and gaining skills. There's no reason to assume that this attack against our cultural sense of thrift will not continue. This is the perfect attack against middle-management: unsleeping automatons that never get sick, go on vacation, or need to be paid health insurance that can produce output that superficially resembles the output of human employees. I see no reason that this will continue to grow until and unless the bubble pops. Even then, a lot of those scrapers will probably stick around until their venture capital runs out.+It's not lol. We are destroying the commons in order to get hypothetical gains. The last big AI breakthrough happened with GPT-4 in 2023. The rest has been incremental improvements. Even with scrapers burning everything in their wake, there is not enough training data to create another exponential breakthrough. All we can do now is make it more efficient to run GPT-4 level models on lesser hardware. I can (and regularly do) run a model just as good as GPT-4 on my MacBook at this point, which is really cool.+This is a regulatory issue. The thing that needs to happen is that governments need to step in and give these AI companies that are destroying the digital common good existentially threatening fines and make them pay reparations to the communities they are harming. Ironically enough, most of these AI companies rely on the communities they are destroying. This presents the kind of paradox that I would expect to read in a Neal Stephenson book from the 90's, not CBC's front page.+Anubis helps mitigate a lot of the badness by making attacks more computationally expensive. Anubis (even in configurations that omit proof of work) makes attackers have to retool their scraping to use headless browsers instead of blindly scraping HTML. This increases the infrastructure costs of the AI companies propagating this abusive traffic. The hope is that this makes it fiscally unviable for AI companies to scrape by making them have to dedicate much more hardware to the problem.+Yes, but this regulation would have to be global, simultaneous, and permanent to have any chance of this actually having a positive impact. Our society cannot currently regulate against similar existential threats like climate change. I have no hope for such regulation to be made regarding generative AI.+In some cases for open source projects, we've seen upwards of 95% of traffic being AI crawlers. For one, deploying Anubis almost instantly caused server load to crater by so much that it made them think they accidentally took their site offline. One of my customers had their power bills drop by a significant fraction after deploying Anubis. It's nuts.+Personally, deploying Anubis to my blog has reduced the amount of ad impressions I've been giving by over 50%. I suspect that there is a lot of unreported click fraud for online advertising.+Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
+19
Clippings/Snowpost.md
+19
Clippings/Snowpost.md
···+You can log in with your [BlueSky](https://bsky.app/) account and publish beautiful static pages to share with the world. That's it!+Read more about Snowpost [here](https://snowpo.st/about), check out some [recent posts](https://snowpo.st/recent), or get started [writing a new post](https://snowpo.st/write).
+230
Clippings/Substack just killed the creator economy.md
+230
Clippings/Substack just killed the creator economy.md
···++[Tyler Denk](https://www.twitter.com/denk_tweets?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)++[](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25)+[Attio](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25) is the AI-native CRM for the next era of companies.+[Connect your email and calendar](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25), and [Attio](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25) instantly builds a CRM that matches your business model — with all your companies, contacts, and interactions enriched with actionable insights.+- [Build powerful AI automations](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25) for your most complex workflows+Fast-growing companies like Granola, Modal, Replicate and more are already experiencing the future of GTM with Attio.+See it for yourself → [try Attio Pro for free now](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25).+[Upgrade Your GTM](https://attio.com/?utm_source=big_desk_energy&utm_medium=newsletter_sponsorship&utm_campaign=BDE-H2Y25)+Last week, they announced that all writers would be required to offer Apple’s in-app purchase (IAP) payment option. That means that Apple will be collecting a 30% fee for all subscriptions purchased on Substack via IAP.+But don’t worry, Substack will automatically set prices higher in the iOS app so their writers take home the same amount (i.e., the cost is passed on to the readers).++Oddly enough, this heavy-handed decision was made unilaterally, without giving writers the ability to opt out. Users responded pretty much exactly how you would have expected in the comment section of the announcement.++It hasn’t even been two full months since Substack raised their $100M Series C, and The Chernin Group (TCG) is already deploying their usual playbook of aggressive growth and revenue extraction at the expense of the original product and vision. This is the same TCG that had previously decimated Food52, Hodinkee, and Cameo.+- Writers had absolutely no say in the decision, despite the very real consequences for their business.+And while the move is obviously terrible for everyone involved (not named Substack or Apple), focusing on the exorbitant fees is entirely missing the forest for the trees. This move is far more insidious.+When writers join the platform, they connect their own Stripe account to Substack. This means that the writer owns the data and billing relationship with their readers, independent of Substack.+When a reader upgrades to pay for a newsletter, under the hood, they become a customer in the writer’s own Stripe account. The writer has full ownership of this transaction and can view, update, and manage billing settings as they please (it’s their customer after all).+Substack charges a 10% fee on all payments simply for calling the Stripe API and transferring funds from the reader to the writer’s Stripe account.++It’s important to note that the writer, at any point, can disconnect their Stripe account from Substack and move it to another platform of their choice.+For example, when writers grow tired of paying Substack a 10% fee for a simple API call, they can simply disconnect their Stripe account and move it to [beehiiv](https://www.beehiiv.com/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com) (which doesn’t extort revenue from its writers).++With Substack’s latest launch, writers are actually ceding control of the billing relationship to Apple, which now owns and controls the subscription. These transactions, subscriptions, and customers will no longer be accessible in their Stripe account.++Most importantly, that means that if writers choose to leave Substack, they won’t be able to port their paid subscriptions over to another platform like they could previously. This predatory platform lock-in is incredibly dangerous for writers. It strips away data and control, while locking them into the platform.+There’s an unwritten rule in the creator economy around data portability, which allows users to export and import critical data across platforms. Data portability is overwhelmingly good for creators.+As much as I would prefer every [beehiiv](https://www.beehiiv.com/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com) user to remain on the platform forever, we make it dead simple for them to leave if they so choose. At any time, beehiiv users can export their content, contacts, and even paid subscriptions and move them to any platform of their choice.+Data portability fuels healthy competition. It lets creators choose the platform that serves them best today, and move freely as their needs evolve tomorrow.+With its latest moves, Substack is blatantly trying to destroy writers’ freedom to choose how to build their businesses. By ceding the billing relationship to Apple, Substack is making yet another attempt to lock users into the platform.+As I (successfully) [predicted back in December](https://mail.bigdeskenergy.com/p/death-by-thousand-substacks), this is all part of the classic playbook deployed by exploitative take-rate businesses:+Patreon raised its take rate from 5% to 12%, Gumroad went from 4% to 10%, and even Etsy bumped theirs from 3.5% to 6.5%.+**2022:** Substack launches an app so *your* readers become *their* users. Writers cede control of the audience relationship as Substack sends automated emails on their behalf, pushing readers to download the Substack app. (Take control of the end user).+++**2025:** Substack severs the billing relationship between its writers and readers so they cannot easily migrate to another platform. (Increase platform dependency).+I’m no investing quant, but if TCG wants to see a return on their investment ($1.1B post-money valuation), you better believe the next step here is to increase Substack’s take rate. And with the inability to migrate your subscriptions elsewhere (as we saw with the latest iOS rollout), what option will writers have other than to accept it?+[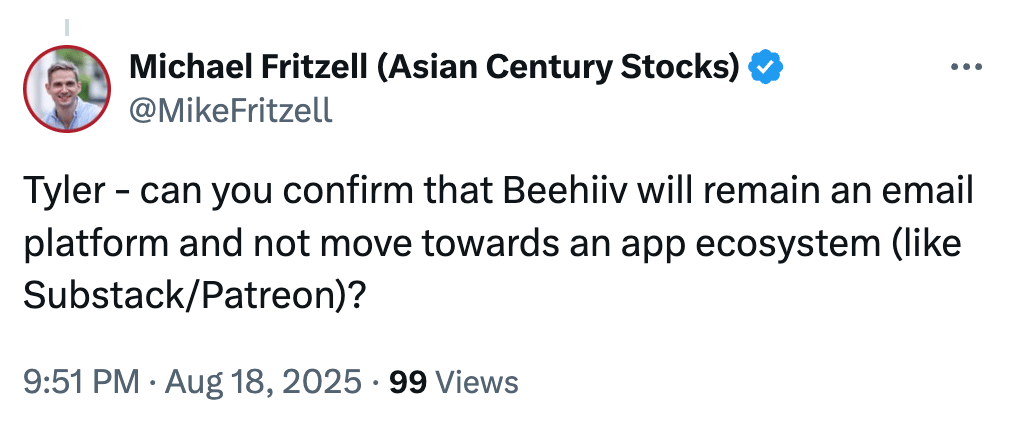](https://x.com/MikeFritzell/status/1957666815083180073?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+Alternatively, you can look to writers like [Oliver Darcy](https://www.status.news/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com), who launched [Status](https://www.status.news/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com) last year on beehiiv. Status has its own unique and distinct brand, retains full ownership of its audience, and keeps 100% of the revenue it earns ($1M+ ARR in their first year btw).+[](https://www.status.news/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+The most sophisticated writers and creators will recognize the importance of having ownership of their business and not ceding control to a platform with misaligned incentives.+Publishers have seen this movie a thousand times before: Facebook, Twitter, Google, and now Substack. If creators can’t trust the platforms built on their backs, it’s time to build something better — ***together***.++*Turn on, tune in, drop out. Click on any of the tracks below to get in a groove — each selected from the full* [*Big Desk Energy playlist*](https://open.spotify.com/playlist/5s8443tfYUq3LLARJwGeYP?si=16012ae913534271&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)*.*+[](https://open.spotify.com/track/3UzmjXtZUncUbprhVYTTAc?si=7d9fcf81d30b4242&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+[](https://open.spotify.com/track/5geqj41FcLoI7PE3LGjNk4?si=a6653424acb84974&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+[](https://open.spotify.com/track/6rCkaw89aoGhunEMTXpSiN?si=139f9a6f0ba34d07&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+[](https://open.spotify.com/track/2lOkBzsfI94veGKJVoksXX?si=21fb69ee58b84e54&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+- The Lux Quarterly Letter was the best thing I’ve read this week ([Lux Capital](https://drive.google.com/file/d/1bnhsfLxo1FShSEXjh4E8Fpn3p7SN2O99/view?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com))+- The insanely valuable company-building principles of Elon Musk ([Founders Podcast](https://podcasts.apple.com/us/podcast/399-how-elon-works/id1141877104?i=1000723471754&utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com))+[](https://denkbot.bigdeskenergy.com/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+Chat with [DenkBot](https://denkbot.bigdeskenergy.com/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com) — my AI clone. It’s trained on everything I’ve ever published and the entire beehiiv knowledge base 🧠.+It’s also trained on my voice, which means you can call it and have full conversations. [Give it a try](https://denkbot.bigdeskenergy.com/?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com) and let me know what you think.+[](https://mail.bigdeskenergy.com/subscribe/PLACEHOLDER/referrals)+[](https://mail.bigdeskenergy.com/subscribe/PLACEHOLDER/referrals)+📥 Want to advertise in Big Desk Energy? [Learn More](https://docsend.com/view/d6uy7rq8w87k2qkf?utm_campaign=substack-just-killed-the-creator-economy&utm_medium=referral&utm_source=mail.bigdeskenergy.com)+[](https://mail.bigdeskenergy.com/p/peak-2025)+[](https://mail.bigdeskenergy.com/p/sunshining)+[](https://mail.bigdeskenergy.com/p/20m-arr)
+261
Clippings/The Binding of Freedom and Intellect.md
+261
Clippings/The Binding of Freedom and Intellect.md
···+description: "The footprint of human intelligence is inseparable from human freedom. Human intellectual freedom - being undetermined yet appropriate - entails indefinite direction over AI and its long-term impacts."+### The footprint of human intelligence is inseparable from human freedom. Human intellectual freedom - being undetermined yet appropriate - entails indefinite direction over AI and its long-term impacts.++*(Some of the ideas in this post are elaborated elsewhere, including [here](https://philpapers.org/rec/CARCBC), [here](https://philpapers.org/rec/CARTCA-19), [here](https://bioling.psychopen.eu/index.php/bioling/article/view/13507), and [here](https://philosophynow.org/issues/168/Rescuing_Mind_from_the_Machines).)*+In their 2007 edited volume, *Artificial General Intelligence*, Cassio Pennachin and Ben Goertzel [introduce](https://link.springer.com/chapter/10.1007/978-3-540-68677-4_1) the collection with a grievance: the field of AI, founded with the aim of constructing a system that “controls itself autonomously, with its own thoughts, worries, feelings, strengths, weaknesses and predispositions,” strayed from the path. The “demonstrated difficulty of the problem” led most researchers towards “narrow AI” - systems constructed for specialized areas, like chess-playing or self-driving vehicles (1).+Their book sought to revitalize the concept of what used to be called “strong AI” with a new designation: “Artificial General Intelligence.” This AGI should have, they argued, the following attributes:+> • the ability to solve general problems in a non-domain-restricted way, in the same sense that a human can;+> • most probably, the ability to solve problems in particular domains and particular contexts with particular efficiency;+> • the ability to use its more generalized and more specialized intelligence capabilities together, in a unified way;+> • the ability to become better at solving novel types of problems as it gains experience with them. (7)+Lest there be any confusion, they qualify these attributes, noting that a system in possession of them must be+> capable of *learning*, especially *autonomous* and *incremental learning*. The system should be able to interact with its *environment* and other *entities* in the environment (which can include teachers and trainers, human or not), and learn from these interactions. It should also be able to *build upon its previous experiences*, and the skills they have taught it, to learn *more complex actions* and therefore *more complex goals*. (8) (emphases added)+Peter Voss, a [contributor](https://link.springer.com/chapter/10.1007/978-3-540-68677-4_4) to the volume, to stock of the AI landscape in 2023 (with co-author Mlađan Jovanović). Their brief article, titled “ [Why We Don’t Have AGI Yet](https://arxiv.org/abs/2308.03598),” was dour:+> AI’s focus had shifted from **having** internal intelligence to utilizing external intelligence (the programmer’s intelligence) to solve particular problems (1).+> extremely unlikely given the hard requirements for human-level AGI such as reliability, predictability, and non-toxicity; real-time, life-long learning; and high-level reasoning and metacognition (2).+I was nevertheless reminded of this history with DeepMind’s recent announcement that a version of Gemini Deep Think correctly (and verifiably) solved 5 out of 6 International Mathematical Olympiad 2025 problems. It is an enormous achievement even if its success does not portend broader application of equal sophistication. And much to the point, my eyes immediately locked on the following line in DeepMind’s [press release](https://deepmind.google/discover/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/), noting that Gemini Deep Think was trained on+> a curated corpus of high-quality solutions to mathematics problems, and **added some general hints and tips** on how to approach IMO problems to its instructions. (emphasis added)+To be sure, the immediate thought here is related to *capability*. The insertion of particular knowledge or other information in the system’s instructions is not-nothing. Each prompt massages a particular part(s) of a statistical distribution of tokens. When testing an LLM’s capabilities, it is necessary to not unwittingly provide the model with the intellectual resources it needs to solve the problem, such that it can merely [approximate](https://arxiv.org/abs/2403.04121) the correct answer by drawing, not quite faithfully but rather through re-combination, from its vast knowledge base (extended with access to tools for web search).+What came to mind was, instead, the ***use*** of a model’s capability; performance, not competence.+It is odd that computational systems of any kind are *directed* towards particular tasks, and even odder that they still require this direction even when their performance on a task is human-level or beyond. It is not as though Gemini Deep Think was *found*, on its own accord, participating in an independently verifiable IMO test; DeepMind researchers instructed it to solve certain problems (with those general hints and tips they generously provided). Neither do other systems like ChatGPT agent do anything other than what one asks of it.+These systems are nonetheless sometimes described as “autonomous,” or in possession of “autonomy” or “agency.” These terms are supposed to mean something.+If we were to ask Pennachin and Goertzel, they would tell us that “autonomous” AI describes a system actively engaged with its environment (both living and non-living entities therein), incrementally learning in the process of engagement, and building more and more complex goals as it effectively solves novel problems. LLMs do not meet this standard, consistent wit the rinse-repeat cycle of instructing an LLM to perform a task or set of tasks, evaluating the output, and setting it into motion on the next task(s).+This does *seem* to be a pretty good characterization of what we mean by *human* autonomy, hence the appeal. But this is not the only possible take.+Luciano Floridi argues that LLMs represent a form of *[agency without intelligence](https://link.springer.com/article/10.1007/s13347-023-00621-y)*, a first-of-its-kind in the history of human technology, quite apart from the kind of agency *with* intelligence we expect from humans.+More bullishly, [Reto Gubelmann](https://link.springer.com/article/10.1007/s13347-024-00696-1) argues that LLMs are not autonomous in the sense provided Kant: they fall on the “mechanism” side of the mechanism-organism distinction, the latter capable of acting according to its own *intents* to engage in *acts* (in this case, speech acts) reflective of the relevant forms of *cognitive and moral autonomy*.+However, Gubelmann *does* argue that LLMs engage in an “autonomous” form of *training*, where the updates to its weights occur without human direction. “Only *ex post*, once it turned out that a trained model establishes new state of the art (SOTA) performance, do humans start to analyze the model to determine its inner functional organization” (18). Indeed, he argues, LLMs engage in the “autonomous” selection of specific functions for specific (internal) components (3-9).+LLMs remain mechanisms, despite this, because their *functioning* cannot be relevantly distinguished, in terms of intent, from their *mal* functioning. Though they could - he argues - one day overturn the distinction given that their training and general-purpose applicability indicate *movement* toward becoming a *non-biological* organism.+These are fascinating views, though I believe quite incomplete if we are interested in characterizing human “autonomy” and evaluating models like LLMs on the basis of this characterization.+I suspect that [Cristiano Cali](https://jeet.ieet.org/index.php/home/article/view/127/126) is closer to my point with his argument that *free will* is a cognitive capacity that allows humans to be *reproductive* and its lack thereof in AI systems has made them *merely* *productive* (towards human ends) (2-3). In particular, that human freedom of will is linked to freedom of action (my thoughts direct my actions), a point recently made by [Nick Chater](http://youtube.com/watch?si=ttIVFuvYTM81nhj5&v=t6oEt27A6Mg&feature=youtu.be), not given from the outside.+Freedom, particularly **intellectual freedom**, is the relevant sort of autonomy. But do humans possess something that could rightly be called “intellectual freedom?” If so, could AI ever replicate it? Or, are we all just meat in the street?+Accepted wisdom today holds that humans are merely biological organisms, the emphasis on *biological* indicating that anything comprised of physical processes within a highly interactive network (i.e., the human body, including the brain) is fundamentally *mechanical*; the behavior, or actions, of these organisms are the results of these internal interactions playing out. In this sense, the human’s actions are no different than their inactions; to act or not to act are each the result, fundamentally, of a massively complex, internal push-and-pull. It is all [determined](https://www.google.com/books/edition/Determined/Sv2nEAAAQBAJ?hl=en&gbpv=0), and being determined, humans are therefore not free to choose (anything).+In a nutshell: **science has not solved every problem, but the universe is material, and we need only give it time before every behavioral determinant is uncovered**.+[Kevin Mitchell et al](https://arxiv.org/abs/2503.19672). are correct to point that that the free will debate, often occurring against that backdrop, is not so much a debate about *whether we have free will*, but whether we can prove that free will is *not* an illusion; determinism—and a skepticism towards compatibilism—are the starting points of inquiry.+Seventeenth-century Cartesians did not see things this way. They did not not begin inquiry as though the goal were to prove free will was not an illusion. Instead, the effort to explain human behavior was deliberate, located within a broader theoretical framework. Indeed, Descartes’ mechanical philosophy *necessitated* a distinction between ordinary matter and the mind. The mechanical philosophy held that the world can be explained as though it were a massive machine, accounting for observed phenomena through “purely physical causes” —except, as [I. Bernard Cohen](https://www.google.com/books/edition/Revolution_in_Science/KniUvcxFtOwC?hl=en&gbpv=0) pointed out, matters of mind and thought.+The mind was held to be non-mechanical. It could not be explained merely through an accounting of physical processes. Descartes’ [overriding concern](https://www.google.com/books/edition/Discourse_on_the_Method/7CkLvOBHnr4C?hl=en) was to ensure that+> if there were machines bearing the image of our bodies, and capable of imitating our actions as far as it is morally possible, there would still remain two most certain tests whereby to know that they were not therefore really men (71-72).+One of the tests, sometimes called the “action test,” need not concern us here, because it does not hold up to scrutiny. The other test—the one of interest—is typically called the “ [language test](https://www.jstor.org/stable/3749220):”+> Of these the first is that they could never use words or other signs arranged in such a manner as is *competent to us* in order to *declare our thoughts* to others: for we may easily conceive a machine to be so constructed that it emits vocables, and even that it emits some correspondent to the action upon it of external objects which cause a change in its organs…but not that it should *arrange them variously* so as *appositely to reply to what is said in its presence*, as men of the *lowest grade of intellect can do* (72) (emphases added).+Descartes [here](https://www.google.com/books/edition/Discourse_on_the_Method/7CkLvOBHnr4C?hl=en) is offering criteria that would reasonably signify the subject (which ‘bears our image’) possesses a mind like our own:+- In doing this, it combines and re-combines words in an appropriate fashion given the context (“arrange them variously” and “appositely to reply”);+- Finally, its use of language in this fashion is entirely *ordinary* and not a feature of a general intelligence which varies between humans (as those of the “lowest grade of intellect can do”).+Descartes also packs into these brief remarks two criteria that are *insufficient* for possession of a mind:+- It merely outputs words in *direct contact* with an external force (“correspondent to the action upon it”).+The problem Descartes was highlighting is the problem of the *ordinary* expression of thought through natural language, an ability apparently out of reach for machines.+Thirty-one years later, French philosopher [Géraud de Cordemoy](https://www.google.com/books/edition/A_Philosophicall_Discourse_Concerning_Sp/FnpnAAAAcAAJ?sa=X&ved=2ahUKEwi166_j7pKPAxX0FmIAHdnxGU4QiqUDegQIEBAG) wrote a book on human speech extending this notion. In it, he acknowledged that words and thoughts are linked in humans, but to possess a mind like our own, it is insufficient that the subject under consideration exhibit “ *the facilness of pronouncing Words* ” to conclude “ *that they had the advantage of being united to Souls* ” (13-14). Mere utterance of words is insufficient for a mind like our own. For Cordemoy, it is not the mere output of words that matters. Rather, it is how words and other signs are *used*:+> But yet, when I shall see, that those Bodies shall make signes, that shall have *no respect at all to the state they are in*, nor to their conversation: when I shall see, that those signs shall agree with those which I shall have made to *express my thoughts*: When I shall see, that they shall *give me Idea’s, I had not before*, and which shall relate to the thing, I had already in my mind: Lastly, when I shall see a *great sequel between their signes and mine*, I shall not be reasonable, If I believe not, that they are such, as I am (18-19) (emphases added).+Following Descartes, Cordemoy extends the original “language test” by providing necessary and sufficient criteria for possession of mind:+- Their use of words lacks a *necessary* or otherwise *fixed connection* with their current state or surroundings (“no respect at all to the state they are in, nor to their conversation”);+- Their words correspond to the *meanings* of the words used by the interlocutor to convey the contents of their mind (“those signs shall agree with those which I shall have made to express my thoughts”);+- Their words convey *novel ideas* which the interlocutor did not previously possess (“give me Idea’s, I had not before”).+- Finally, there is a *complementarity* between the use of words by the subject and the interlocutor (“a great sequel”).+Descartes and Cordemoy thus took ordinary human language use to be non-mechanical and illustrative of human free will (which evidences itself perhaps most strikingly, though not exclusively, through language use). This is the problem of how humans ordinarily convey the contents of their minds to other by communicating new ideas through novel utterances that correspond with their thoughts, done with no apparent fixed relationship with one’s inner physiological state nor local context.+It is easy, with the benefit of history, to misinterpret the full scope of Descartes’ problem of ordinary language use. Indeed, in popular histories of science, like Jessica Riskin’s (excellent) *[The Restless Clock](https://www.google.com/books/edition/The_Restless_Clock/GRtlCwAAQBAJ?hl=en&gbpv=0)*, Descartes’ brief remarks on the matter are described as the claim that+> a physical mechanism could never arrange words so as to give meaningful answers to questions. Only a spiritual entity could achieve the limitlessness of interactive language, putting words together in indefinitely many ways (63).+Riskin implicitly addresses only *part* of what Descartes was noting to be off-limits to a machine: the infinite generativity of its language from its finite components.+Remember: the mechanical philosophy held that observed phenomena could be explained in terms of their physical composition and interactions therein. Any physical object, however, is *finite*. Thus, no physical object could account for anything that yields *infinite* generativity.+The problem is that human language *is* an infinite system; the *infinite use of finite means*. The phrase, a modification of Wilhelm von Humboldt’s claim that language, to ‘confront an unending and truly boundless domain,’ must “ [therefore make infinite employment of finite means](https://www.google.com/books/edition/Humboldt_On_Language/_UODbGlD4WUC?hl=en&gbpv=0) ” (91), was popularized by Noam Chomsky. The point is that human language is truly *unbounded*; capable of infinite re-combination of words into structured expressions that express meanings, often novel in the individual’s history or in the history of the universe, yet nonetheless expressed with relative ease and understood by others with equal facility. The unbounded capacity to produce form/meaning pairs.+Fascination with this human ability has a notable intermittency about it throughout modern history before the mid-twentieth century. Every so often, someone would hint at or raise the problem, observing its significance, but finding no full resolution.+Danish linguist [Otto Jespersen](https://www.grammainstitute.com/wp-content/uploads/2024/03/The-Philosophy-of-Grammar-PDFDrive-.pdf) (another frequent Chomsky citation) wrote in 1924 critically of the then-prevailing wisdom that human language is 'dead text,’ lamenting the field’s “too exclusive preoccupation with written or printed words…” (17). It was the distinction between ‘formulaic’ expressions (e.g., “How do you do?”)—which are essentially fixed, amenable only to changes in the *inflection* used to speak it—and “free expressions”—which must be created on-the-fly to “fit the particular situations” (19) that so intrigued him. The word variability that the individual selects in the moment—engaging in this “free combination of existing elements” (21)—to convey the precise details of a *new* situation nonetheless conforms to a “certain pattern” or “type” without the need for “special grammatical training” (19).+One finds in Jespersen’s writing a duality: language is a *habitual*, *complex action* by the speaker, the *formula* used to speak determined by *prior* situations, but must in *new* situations *tailor* these habits to express *what has not been expressed before*. “Grammar thus becomes a part of linguistic psychology or psychological linguistics” (29). Jespersen’s account of human language is not quite what we would call “internalist” today (being underspecified in this respect), though he notably dances around the question of how individuals ‘freely express’ their thoughts *at all*, focusing instead on the fact that they are innovative—selecting from an unbounded class—in daily speech.+This problem of infinite generativity from finite means was reformulated by generative linguists in the mid-twentieth century based on works by [Alan Turing](https://londmathsoc.onlinelibrary.wiley.com/doi/10.1112/plms/s2-42.1.230), Alonzo Church, and Kurt Gödel, among a few others. The establishment of [recursive function theory](https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2014.00382/full) (now called computability theory) allowed scholars to conceive of the possibility of infinite generativity (human language) from a finite system (the brain). The unboundedness of human language could now be accounted for by postulating a computational system specific to language (the language faculty). Turing computability paved the way for conceiving of an idealized “ [neurobiological Turing machine](https://experts.arizona.edu/en/publications/rethinking-universality).”+On returning to Descartes’ problem, things look different. Descartes and the later Cartesians had no knowledge of the possibility of a Turing machine. Thus, no distinction was made between the capacity for infinite generativity from a finite system and the *use* of this system in arbitrary circumstances. There simply was *the* problem of ordinary, creative language use.+Yet, Turing showed their ignorance about unboundedness and its implications to be unnecessary. Infinite generativity from finite means can be conceived without reference to a “spiritual entity.” A “physical” mechanism can yield unbounded outputs.+This reformulation mid-century entailed new distinctions. One is that “language” can now be conceived as an internal generative procedure rather than spoken or written words, as it is the computational system that structures them. Another is that this language faculty is now one component of linguistic production; that is, the language faculty must interface with other cognitive systems during its use.+Notice what has *not* been explained by this postulation: the postulation of an internal computational system is tantamount to claiming that humans possess a domain-specific knowledge of language, or competence. *Yet, the* *actual use of this knowledge in arbitrary circumstances remains untouched*. That is, *performance* is not explained.+Now we can be clearer about what Descartes’ problem was really all about. It was not a problem of constructing of an input-output mechanism that could be set into motion to output human-like sentences over an indefinite range, *for they had no such conception of computability*. The problem of ordinary language use subsumed both the infinite generativity from finite means and the uncaused expression of thought through language. The first part was given a clarity in the twentieth century. The second part remains where it was.+What the Cartesians observed in the seventeenth century is today operationalized by generative linguists according to three conditions:+**Stimulus-Freedom**: There is no identifiable one-to-one relationship between stimulus and utterance; it is not *caused,* in any meaningful sense of the term, by either external conditions or internal physiological states.+**Unboundedness**: Ordinary language use selects from an unbounded class of possible structured expressions.+**Appropriateness to Circumstance**: Despite being stimulus-free and unbounded, language use is routinely appropriate in that it is judged by others who hear (or otherwise interpret) the remarks as fitting the situation, perhaps having made similar remarks themselves in the speaker’s position.+Human beings thus possess, as [Chomsky](https://www.google.com/books/edition/Cartesian_Linguistics/oxJthMb8YM4C?hl=en&gbpv=0) summarizes,+> a species-specific capacity, a unique type of intellectual organization which cannot be attributed to peripheral organs or related to general intelligence and which manifests itself in what we may refer to as the “creative aspect” of ordinary language use+> Thus Descartes maintains that language is available for the free expression of thought or for appropriate response in any new context and is undetermined by any fixed association of utterances to external stimuli or physiological states (identifiable in any noncircular fashion) (60).+Human language use is *neither* determined (being stimulus-free and unbounded) *nor* is it random (appropriate). It is not an input-output system. We are thus far from where we began: this is not a more ambitious version of the “general intelligence” defined by Pennachin and Goertzel. Rather, it is qualitatively different; “a unique type of intellectual organization…”+Human beings are capable of voluntarily deploying their intellectual resources through natural language in ways that are *detached* from the circumstances they find themselves in yet do so in ways that are *appropriate* to those circumstances. There is a real experience, sometimes glossed as a “ [meeting of minds](https://www.ceeol.com/search/article-detail?id=223974),” of individuals converging on their interpretations of a natural language expressions without relying on fixed stimuli do so. Importantly, they can both *produce* new expressions and find *others’* novel expressions appropriate over an unbounded range.+Attempts to refute this notion of a “creative aspect of language use” are bafflingly limited relative to the larger free will debate.+The most plausible path is to suggest one of two things: human language is not stimulus-free; or the appropriateness of language use is an illusion.+On the first: There are no pre-fixed uses of human language; no set of stimuli that reliably and predictably trigger the use of language. A human can use language to plead their innocence; to admit their guilt; to convey useful information; to lie, cheat, and steal; to comfort and console; to tell their partner they love them; to admit they never truly loved them; to reflect on a life well-lived; to lament wasted time; to argue and debate; to tell a friend how they feel; to construct a fictional world; to speak of the goings-on in other galaxies, of lives lived centuries before, of the beginning of time itself (and whether it began at all); to sing and write; to conduct science and philosophy; to speak to a president from the surface of the moon; to muse over what the future may bring…+Human language is stimulus- *free*. It is free in a way that we can only describe by observing our internal states and the unfixed utterances of others who appear to have minds like our own. To attempt a post-hoc tracing of an utterance back to its original context in search of a cause merely leaves one with post-hoc attribution under the guise of causality, a point Chomsky made in 1959. Nor can a deterministic, mechanical conception of internal processes contend with the fact that language use is routinely appropriate to *others* whose physiological states are not relevant to the speaker. Why do the mechanisms of my internal state, operating purely deterministically (or, at best, randomly) produce utterances which align with *your* mental state, undergoing its own deterministic operations?+A causal explanation for language use depends on *individuals using language* —if they choose to use it at all—defeating the causal enterprise from within.+There is no meaningful sense in which any of these uses of human language can be affixed to stimuli; to account for them as signals reliably or exclusively recruited by specific factors in the local context, like the knee’s [reflex](https://www.colinmcginn.net/freedom-and-bondage-in-psychology/) when tapped. The best one can do is to assign to these uses of language an endless series of “ [putative](https://www.ceeol.com/search/article-detail?id=223974) ” causes, as if the words Neil Armstrong spoke to Nixon were the result of a “Nixon-calling-from-Earth” cause. At this point, one is merely pairing up language uses with the local environment, again falling into the trap of post-hoc attribution.+We somehow [specify our intent](https://www.ceeol.com/search/article-detail?id=223974) in our language use, likewise recognizing it in others’, a fact that seems to make the concept of stimulus-control inadequate to the problem.+Each of these uses is a deployment of intellectual resources *because* human language regulates form/meaning pairs over an *unbounded* range. Yet, human language could conceivably have been reliant on a fixed set of stimuli with which its use was invariably associated. It happens to not be this way. Human beings impose on the world their intellectual footprint on accord of their own desire to do so. Attempts to reduce language use to [communicative purposes](https://tedlab.mit.edu/tedlab_website/researchpapers/Fedorenko_Piantadosi_Gibson_2024.pdf) is to fall into the trap that so captivated Skinner: that one can project onto this phenomenon a theoretical construct—in this case, a tool for communication—that is so emptied of content by the time one returns to its basic descriptive facts as to be useless for explanation.+On the second: it is tempting to become exasperated with this claim about intellectual freedom and suggest that the problem can be resolved by ridding ourselves of the “appropriateness” condition. This is done, perhaps with reference to our status as mere biological organisms, by deeming it an illusion. Therefore, with only unboundedness and stimulus-freedom remaining, the problem seems to vanish.+Yet, deeming appropriateness an illusion merely brings us back right where we began: if language use is both unbounded and stimulus-free yet its convergence with the thoughts of others is some kind of illusion, *then we have merely re-stated the problem in different terms*. Any attempt to explain *[how](https://www.ceeol.com/search/article-detail?id=223974)* this illusion could even exist brings one right back to the original problem.+In contrast, input-output systems are within our range of understanding. A computational device like an LLM receives an input value, performs an operation over that input value to transform it, and then outputs that transformed value. When researchers and engineers say they do not understand how neural networks, including transformers, work, they are not speaking at this level of analysis (see, for example, [this recent piece](https://www.verysane.ai/p/do-we-understand-how-neural-networks)).+The extent to which AI can impose its intellectual footprint on the world hinges in part on the extent to which it can overcome its need for human direction. I do not believe such a development is forthcoming or plausible.+LLMs do as we tell them. If they tell a story, it is because we told them to; if we ask them to predict the future, it is because we told them to; if they conduct science, it is only because we told them to make new discoveries; if an LLM wins gold at the IMO 2025, it is because we told it to solve IMO problems. To the point: they output values because we direct them to through input values.+LLMs lack freedom. They lack choice. LLMs are stimulus-controlled, “behaving” in exactly the way one expects of a device that is “ [impelled](https://inference-review.com/article/the-galilean-challenge) ” to act but never “inclined.”+Most remarkably, an LLM is impelled by the human creative aspect of language use, always requiring that humans act as a prime mover for whatever outputs—of whatever sophistication—they yield. Their “intellects,” insofar as we use the term, are bounded by context (both internal and external). Their binding to human-given stimuli means that they do not “use language” appropriately because they do not “use language” at all, at least not in the sense of freedom of identifiable stimuli. In this way, their language use is *functional*; they exist in a functional relationship with with externally-provided goals and internally-programmed instructions (echoing Gubelmann’s argument against current LLM autonomy).+Fears of runaway AI hinge on computational systems overcoming the determinacy of computation itself. Intelligence, it is thought, is the necessary ingredient, and more of this will yield systems that develop independent motives that see them fully surmount their binding to internal and external stimuli. Computation is unlikely to ever yield such abilities. It is more plausible to imagine the scaffolding of the world by intelligent machines—matching or exceeding a wide range of capabilities so enjoyed by humans—without the will to *use* their intellects as we do.+Should we doubt this, we need only remind ourselves of Descartes’ substance dualism, where “mind” was distinguished from all other “physical” phenomena in the natural world, belonging to its own domain, for which the language test was merely a way of detecting it. We (typically) adopt no such dualism today. If a computational system—or any other mechanical system—exceeds human ability measured by performance output (think: calculators, Chess software, trains, bulldozers, etc.), we do not (typically) attribute to such systems possession of a particular *substance* called “mind;” something detectable in the real world through tests, like the Imitation Game or mathematics benchmarks or the distance a train can travel without refueling. They *perform*,and we attempt to *characterize* them with terms like “reasoning,” “thinking,” “intelligence,” and so forth, reflecting only our immediate understandings of these attributes as we believe they characterize our own cognitive capacities. To construct systems that are “generally intelligent” may be socially transformative, but nothing will have fundamentally changed with respect to the intellectual freedom that apparently only humans exhibit. General AI, in this respect, will share the same fundamental limitation as Narrow AI—the addition of “General” will signify only our own sense of their capabilities in our practical arrangements or theories of human cognition. There is no “second substance” awaiting our discovery.+The future of AI is therefore a human matter, and potentially a bright one, should those efforts be steered appropriately. The trajectory remains an outstanding question. We will not know for some time how this turns out, even with LLMs.+I expect a great deal of disappointment and disillusionment once that time comes. I imagine Descartes’ problem and all the baggage it carries will lead two opposing sides to a mutual conclusion: that humans stubbornly remain in control of their fates and that our freedom is precisely why we can create the beauty we desire with our technologies.+[^2]: The most impressive outputs I have gotten from LLMs, usually some variant of Gemini, always rely on my prompts giving the model a leg-up. They never hit on the idea I would *like* them to hit on without my direction. Presented with a subject I feel comfortably knowledgeable on, they are *quite capable* of approximating in noticeable detail the ideas that I *urge* them to approximate. Yet, they never do anything other than approximate. Even backs-and-forth on a given subject will have them— *very*, *very* impressively—bounce around ideas that I know are out there because the subject is niche enough for me to be among the participants! (A perk of writing on niche subjects is that you can easily identify derivative work.) Nor do LLMs do what I took for granted as a student: yes, a given assignment (prompt) might be interesting, but maybe that assignment is not as interesting as this *other* line of thought+[^3]: We need not do this, for what it’s worth. But if one wants a sense of where computational systems stand today in relation to the *fullest* sense of “autonomy” or “autonomous” action, we have exactly one data point for comparison: humans.+[^4]: I’m often reminded of a professor I had as an undergraduate student—a Vietnam War vet who taught philosophy. He frequently told stories of the war. One such story: somewhere in Vietnam (I never found out where), the men were holed up in a bunker anticipating that the Viet Cong would imminently attack. You can imagine the conditions. One of them, as they were waiting, said: “ *We’re all just meat in the street*.” The line must have stuck with my professor, so much so that he decided to pose it as a question in Intro to Philosophy courses. It’s stuck with me, too.+[^5]: Put another way: human functioning is no different than human *mal* functioning, each resulting from the same internal push-and-pull.+[^6]: Though some 18th century critics, like [La Mettrie](https://www.google.com/books/edition/Man_a_Machine/GKYLAQAAIAAJ?hl=en&gbpv=0), certainly did.+[^7]: One reason why you might see some cognitive scientists expressing concern about the amount of computing power used by a model to handle novel problems—even successfully—is that it diverges sharply from the on-the-fly, resource-limited facility with which linguistic novelty is dealt with. If humans are the benchmark, something’s not right there.+[^8]: Taken against Jespersen and the Cartesians before him, the behaviorist fixation with studying only “observables” in a speaker’s environment can be seen as a regression, having retreated from an adequate description of what occurs in ordinary language use.+[^9]: As Charles Reiss recently argued in a [spicy but sharp piece](https://www.researchgate.net/publication/373717456_Research_Methods_in_Armchair_Linguistics), Chomsky’s argument in *Syntactic Structures* (1957) that finite state models could not serve as adequate models of the English language has to do with this unboundedness—a finite state machine that cycles through a series of pre-determined states (the classic case being the options on a vending machine) is not unbounded. More than this, though, the genius is in the following observation: given that *any* human child can learn *any* human language provided that they are exposed to it during normal development means that a finite state model would not be adequate for *any* human language *because* it is not adequate for English!+[^10]: This may be because it is largely unknown, in part because Chomsky has sometimes used the term “creative aspect of language use” to mean [two different, overlapping things](https://www.jstor.org/stable/20115957): recursion and voluntary use. Though, he has been clear since 1966 about the distinction, yet proponents and critics of generative grammar often think the term only refers to the former.+[^11]: Note that this does not include only the *act* of speaking but also the *content* of what is said.+[^12]: Doubting intellectual freedom would merely leave us with a bizarre idea: that humans are bouncing around the world either deterministically or randomly (or both), due to both internal and external stimuli, yet somehow manage to output sentences that are appropriate to given circumstances over extended periods and across an indefinite range of situations. But this is clearly inadequate. Our words are *tuned* to the circumstance though not *caused* by the circumstance.+[^13]: A separate model or other type of software could serve as the proximate stimulus, too, but the root is always human.+[^14]: On the matter of Kantian autonomy and its relevance to the creative aspect of language use, [Liam Tiernaċ Ó Beagáin](https://philpeople.org/profiles/liam-tiernac-o-beagain) is working on this issue (and I eagerly awaiting the work).+[^15]: Turing wrote in 1950 an essay that is structured in an almost deliberately confusing way, dismissing the question of “Can machines think?” for the more tractable question, “Can a machine pass the Imitation Game?” (only to again raise the problem of thinking machines afterwards!). The move was [strategically wise](https://www.tandfonline.com/doi/full/10.1080/00033790.2023.2234912) on Turing’s part, reflecting a similar lowering of expectations for the field of intelligent machinery. The goal was not to *explain* human thought or intelligence, but merely to become comfortable with the idea of intelligent machinery *so that we may begin building what we can call “intelligent machines*.”+But this has by now been misinterpreted as either (a) A reason to never determine what we mean by these terms, nevertheless feeling that their attribution to systems today signifies a great leap (despite their function as a mere terminological choice); or (b) A reason to assume that attributing a term like “intelligence” to machines tells us anything whatsoever about “human intelligence.” See [here](https://vincentcarchidi.substack.com/p/turing-is-not-your-therapist) for more.
+65
Clippings/ml5 - A friendly machine learning library for the web..md
+65
Clippings/ml5 - A friendly machine learning library for the web..md
···+description: "ml5.js aims to make machine learning approachable for a broad audience of artists, creative coders, and students. The library provides access to machine learning algorithms and models in the browser, building on top of TensorFlow.js with no other external dependencies."+Welcome to the ml5.js project! ml5.js is an open source library with a goal of making machine learning approachable for a broad audience of artists, creative coders, and students. Drawing inspiration from [Processing](https://processing.org/) and [p5.js](https://p5js.org/), ml5.js aims to bridge the gap between the technical complexity of machine learning and the creativity of beginners and artists. The library provides access to machine learning algorithms and models in the browser, building on top of TensorFlow.js.+The project began as a collaborative effort at [NYU's ITP program](https://tisch.nyu.edu/itp), involving contributions from students, researchers, faculty, and alumni. Inspired by the p5.js project's focus on making coding accessible and inclusive, ml5.js aims to expand this mission to the domain of machine learning. Initial work on the project was supported by a [Google Research Award](https://www.nyu.edu/about/news-publications/news/2018/january/itp-professor-daniel-shiffman-granted-google-faculty-research-aw.html), which helped to formalize the relationship between TensorFlow.js and ml5.js.+A key feature of ml5.js is its ability to run pretrained models for interaction. These models can classify images, identify body poses, recognize facial landmarks, hand positions, and more. You can use these models as they are, or as a starting point for further learning along with ml5.js's neural network module which enables training your own models.+The ml5.js library comes with code examples and educational materials with a goal of emphasizing ethical computing and opening the door for discussion on bias in data and machine learning. We're dedicated to building user-friendly machine learning for the web, and we're glad you're here!+ml5.js is heavily inspired by the work of [The Processing Foundation](https://processingfoundation.org/). Learn more about the history and origins of the ml5.js project in the [ITP Adjacent article](https://itp.nyu.edu/adjacent/issue-3/ml5-friendly-open-source-machine-learning-library-for-the-web/) and on [medium.com/@ml5js](https://ml5js.medium.com/).+ml5.js is a community interested in exploring and empowering the creative and ethical application of machine learning. This Code of Conduct is intended to foster a community that is open to anyone interested in joining that exploration.+We are a community of, and in solidarity with, people from every gender identity and expression, sexual orientation, race, ethnicity, size, ability, class, religion, culture, age, skill level, occupation, and background. We acknowledge that not everyone has the time, financial means, or capacity to actively participate, but we recognize and encourage involvement of all kinds. We facilitate and foster access and empowerment. We are all learners.+We accept the claim that technology is a reflection of society, its histories, and its politics. We reject the claim that any technology is neutral and acknowledge that every technology has the potential to do as much harm as good. We acknowledge that when technologies cause harm, the harm disproportionately affects Black/Indigenous, People of Color (BIPOC) queer, trans, disabled, femme, low-income, survivors, and all other marginalized bodies and communities. With this understanding, we work to intentionally engage these groups when hosting, participating in, or developing events (e.g. workshops or meetings), materials (e.g. courses, syllabi, resources), and software (e.g. the ml5.js library, examples, and related and supporting code).+As part of the ml5.js Code of Conduct, we pledge to design, build, and use ml5.js in a way that centers the aforementioned marginalized bodies and communities first, striving to always confront our biases, privileges, and ignorances for our own good and society at large.+- We welcome newcomers and prioritize the education of others. We do not assume knowledge or imply there are things that somebody should know. We strive to approach all tasks with the enthusiasm of a newcomer because we believe that newcomers are just as valuable in this effort as experts.+- We consistently make the effort to actively recognize and validate multiple types of contributions.+[Read more about the development of the ml5 code of conduct and software license](https://medium.com/ml5js/a-new-code-of-conduct-and-license-for-ml5-js-6b0e4c109b76)+ml5.js is supported by the time and dedication of open source developers from all over the world. We are artists, designers, technologists, researchers, educators, students, scientists, developers, parents, children, and everything in-between. We are proud of our [growing list of contributors](https://github.com/ml5js/ml5-next-gen?tab=readme-ov-file#contributors-).+The design and development of ml5.js is currently organized via a joint collaboration between ITP/IMA at Tisch School of the Arts and the IMA program at NYU Shanghai. Development is supported in part by a grant by the Shanghai Frontiers Science Center of Artificial Intelligence and Deep Learning.+Initial funding for this project was provided by a [2018 Google Research Award grant at ITP/IMAprogram](https://www.nyu.edu/about/news-publications/news/2018/january/itp-professor-daniel-shiffman-granted-google-faculty-research-aw.html).+Website design and development is by J.H. Moon, Quinn Fangqing He, Alan Ren, Apoorva Avadhana, Jo Heun Lee, Miaoye Que, Myrah Sarwar, Ozioma Chukwukeme, and Pacey Xiaozao Wang, and supported by Gottfried Haider, Peter Ziyuan Lin, and Dan Shiffman.+The website is based on [the original ml5.js website](https://archive.ml5js.org/#/) which was designed with ❤ by Milan Gary, Nicole Lloyd, and Arnab Chakravarty and developed by Wenqi Li, Joey Lee, and Dan Shiffman.
+1
-1
_config.yml
+1
-1
_config.yml
···-exclude: ['_includes/notes_graph.json', 'caret', '.env', 'gemset.nix', 'fission.yaml', 'blog.code-workspace', 'netlify.toml', '_ignored', '_archive', '.vscode', '.obsidian', '.gitignore', '.github', 'README.md', "_template", ".obsidian"]+exclude: ['_includes/notes_graph.json', 'caret', '.env', 'gemset.nix', 'fission.yaml', 'blog.code-workspace', 'netlify.toml', '_ignored', '_archive', '.vscode', '.obsidian', '.gitignore', '.github', 'README.md', "_template", ".obsidian", 'Clippings']